World4RL: Diffusion World Models for Policy Refinement with Reinforcement Learning for Robotic Manipulation
Abstract
Robotic manipulation policies are commonly initialized through imitation learning, but their performance is limited by the scarcity and narrow coverage of expert data. Reinforcement learning can refine polices to alleviate this limitation, yet real-robot training is costly and unsafe, while training in simulators suffers from the sim-to-real gap. Recent advances in generative models have demonstrated remarkable capabilities in real-world simulation, with diffusion models in particular excelling at generation. This raises the question of how diffusion model-based world models can be combined to enhance pre-trained policies in robotic manipulation. In this work, we propose World4RL, a framework that employs diffusion-based world models as high-fidelity simulators to refine pre-trained policies entirely in imagined environments for robotic manipulation. Unlike prior works that primarily employ world models for planning, our framework enables direct end-to-end policy optimization. World4RL is designed around two principles: pre-training a diffusion world model that captures diverse dynamics on multi-task datasets and refining policies entirely within a frozen world model to avoid online real-world interactions. We further design a two-hot action encoding scheme tailored for robotic manipulation and adopt diffusion backbones to improve modeling fidelity. Extensive simulation and real-world experiments demonstrate that World4RL provides high-fidelity environment modeling and enables consistent policy refinement, yielding significantly higher success rates compared to imitation learning and other baselines.
Method
World4RL Framework Overview
World4RL consists of two stages: pre-training and policy optimization. In the pre-training stage, the diffusion transition model is trained on task-agnostic data to generalize across diverse dynamics, the reward classifier is trained on task-specific data annotated with binary success labels, and the policy is trained via imitation learning to provide a stable initialization. In the policy optimization stage, the pre-trained world model is frozen and used as a simulator, while the policy is refined with PPO under sparse rewards through imagined rollouts. This design improves both sample efficiency and safety, while enabling consistent gains over the initial gaussian policy.
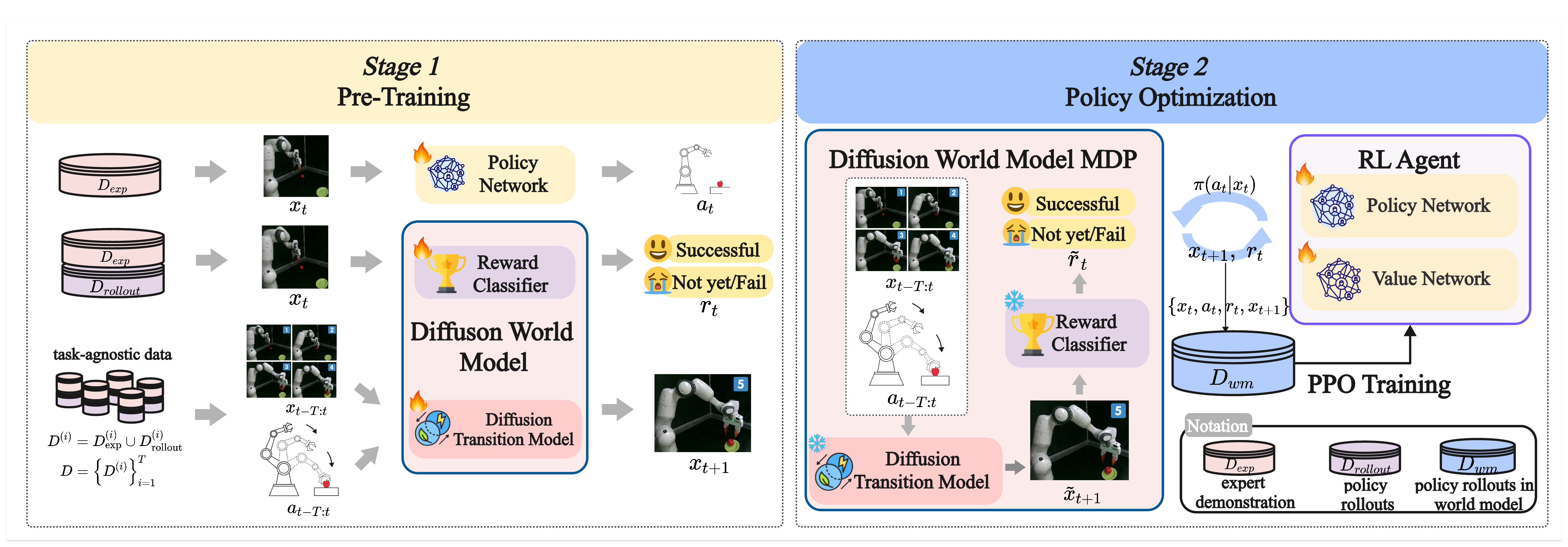
Figure 1: World4RL Framework Overview.
Design of Diffusion Transition Model
For each action dimension , given bin values , we map to its two nearest bins: with and , where denotes the two-hot weight vector for the i-th action dimension.
For example, suppose the action is \(a_i=0.14\), the action range is \([0,1]\), and we use \(K=10\) uniform bins \(B=\{0.0, 0.1, \ldots, 1.0\}\). The two nearest bin edges are \(b_k=0.1\) and \(b_{k+1}=0.2\).
A one-hot encoding chooses the closer bin (0.1), producing:
[0, 1, 0, 0, 0, 0, 0, 0, 0, 0].
In contrast, the two-hot encoding linearly interpolates between the two neighbors:
\[
t_i[k] = \frac{b_{k+1}-a_i}{b_{k+1}-b_k} = \frac{0.2-0.14}{0.1} = 0.6,\qquad
t_i[k+1] = \frac{a_i-b_k}{b_{k+1}-b_k} = \frac{0.14-0.1}{0.1} = 0.4.
\]
This yields:
[0, 0.6, 0.4, 0, 0, 0, 0, 0, 0, 0].
Thereby, two-hot encoding provides a lossless and differentiable representation that better handles continuous action inputs in robotic manipulation tasks.
Based on this, the diffusion transition model \(D_{\theta}\) is designed to predict the next observation through a denoising process conditioned on historical observations \(x^{0}_{t-T:t}\) and encoded actions \(z_{t-T:t}\).
Video: Diffusion Transition Model Architecture
Experiments Results
In experiment, We evaluated World4RL on video generation and policy execution in simulation and on a real Franka robot.
Simulated Robotic Manipulation Environments
The following quantitative evaluation and video rollout results consistently demonstrate the superiority of diffusion-based architectures in preserving temporal consistency and visual fidelity.
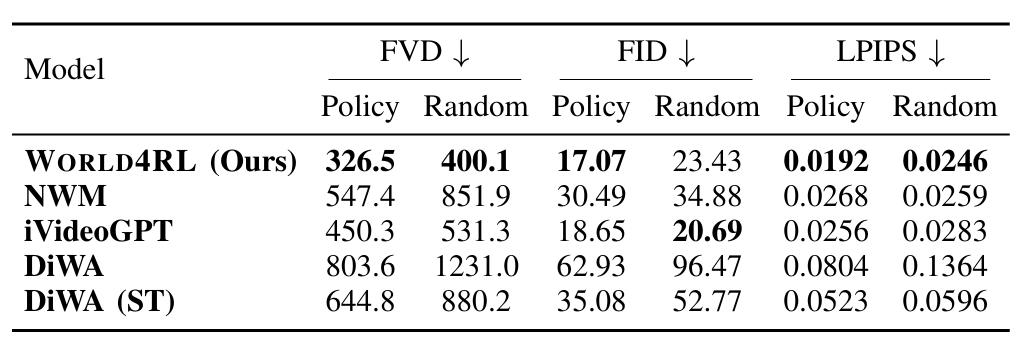
Quantitative results on video prediction. “ST” denotes single-task training.
Visualization of predicted rollouts on the coffee-pull task. The ground-truth (GT) trajectory reflects a failed execution. World4RL successfully captures this failure trajectory, whereas all baseline models fail to do so.
Simulation Performance
In simulation experiments, with policy refinement, we see a significant improvement over the pre-trained policy, achieving a 67.5% success rate across six Meta-World tasks, and further surpassing imitation learning, offline RL, and planning methods.
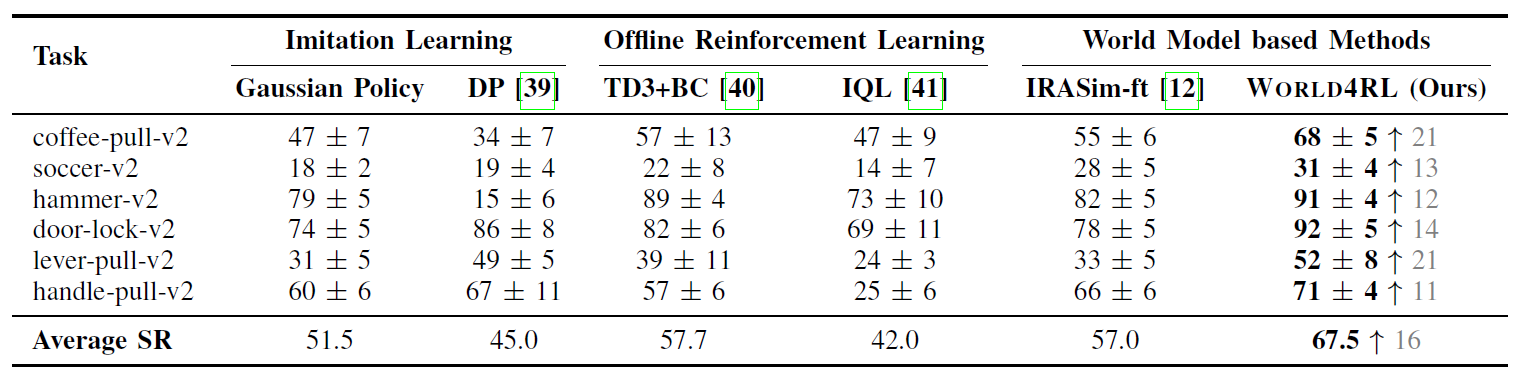
Success rate of different methods on Meta-World benchmark. The notation ↑n indicates the absolute improvement over pre-trained gaussian policy.
World4RL also achieves comparable performance with only expert and policy rollout data, while RLPD and Uni-O4 require 346k and 470k online steps, respectively, to reach the same level. This demonstrates the strong sample efficiency of World4RL, making it particularly suitable for real-robot deployment where online interaction is expensive and limited.
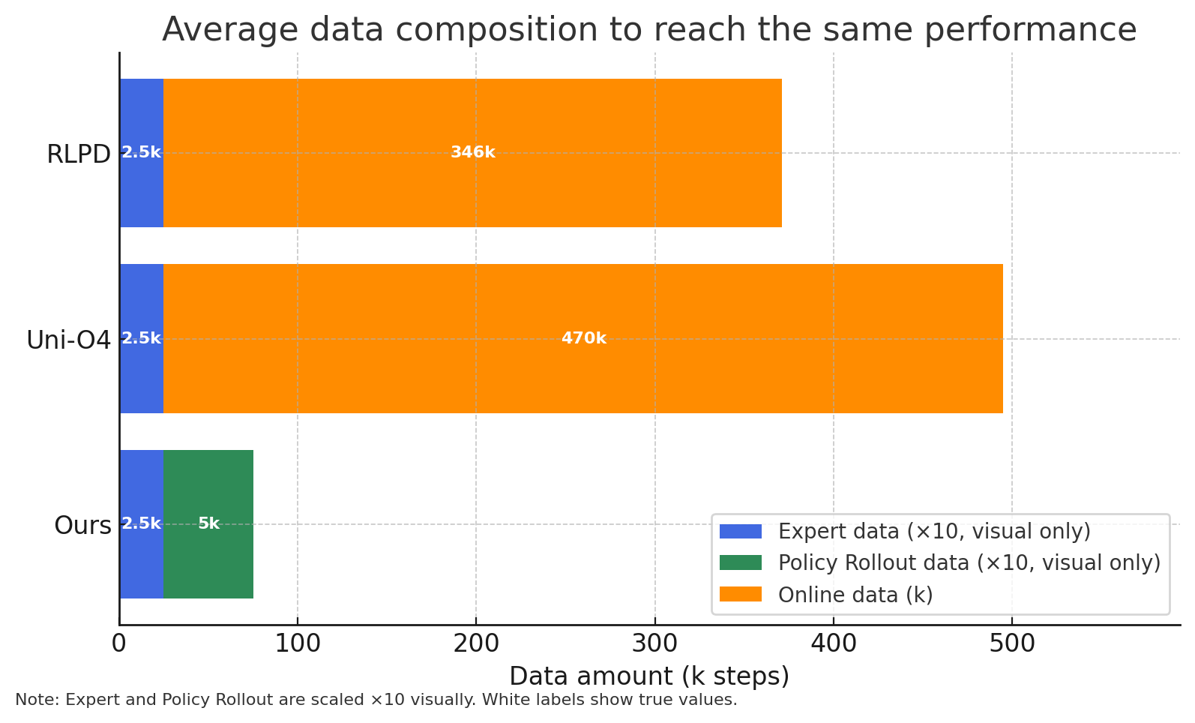
Comparison of online sample efficiency.
Real-World Performance
On real-world tasks, World4RL reachs 93.3% success, significantly outperforming diffusion policies and the pre-trained gaussian policy.
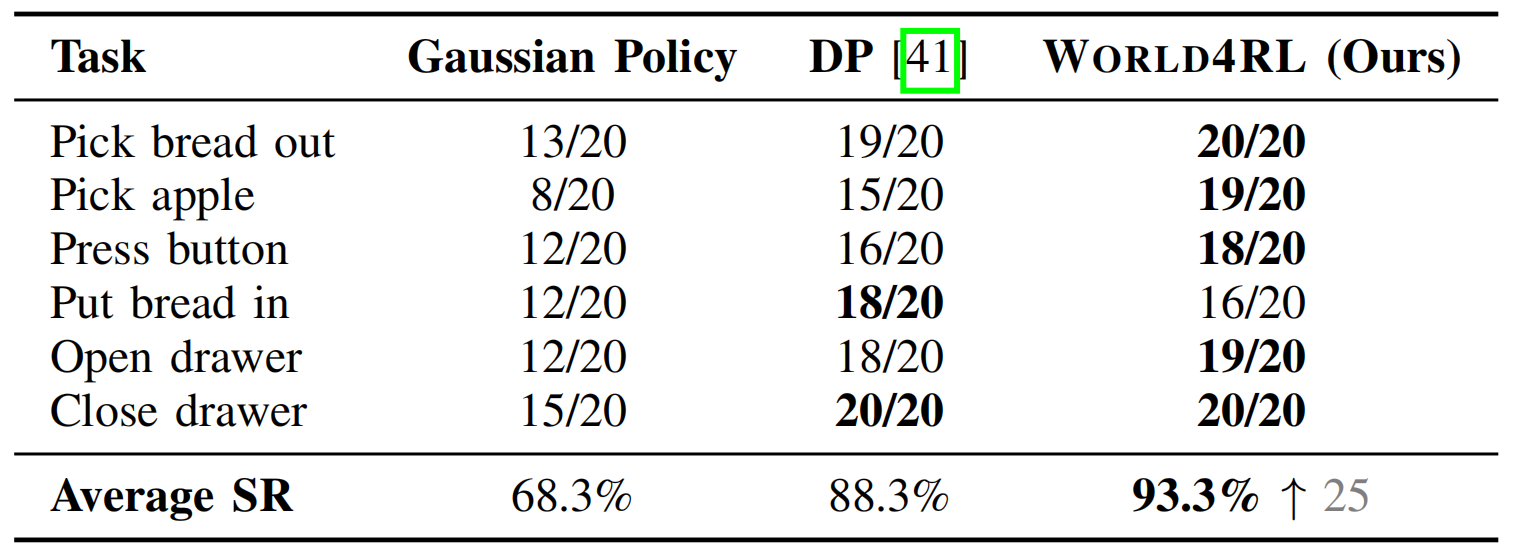
Success rate of different methods on real-world tasks.
Beyond achieving higher success rates, we also observe that policies fine-tuned with World4RL tend to execute tasks more decisively, quickly and accurately. For example, in the put bread in task, the fine-tuned policy promptly performs the grasping and placing actions, whereas gaussian policy and diffusion policy often show hesitation or linger in intermediate states without committing to task completion.
| TASK Name | Pre-trained Policy (Gaussian Policy) |
DP | World4RL |
|---|---|---|---|
| pick apple | |||
| push button | |||
| put bread in | |||
| put bread out | |||
| pull coffee | |||
| close drawer |
Visualization of real-world performance.